
DeepSeek-V3是什么?
DeepSeek-V3 是由深度求索公司推出的一款全新发布的自研 MoE(混合专家)模型,旨在突破当前大语言模型的性能瓶颈。通过 671B 参数和 37B 激活专家,DeepSeek-V3 在 14.8T token 的大规模预训练上取得了显著进展,展现出与世界顶尖闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet)相当的表现。该模型在多项标准评测中超越了 Qwen2.5-72B 和 Llama-3.1-405B 等开源模型,成为当前最强大的开放模型之一。

DeepSeek-V3的核心特点
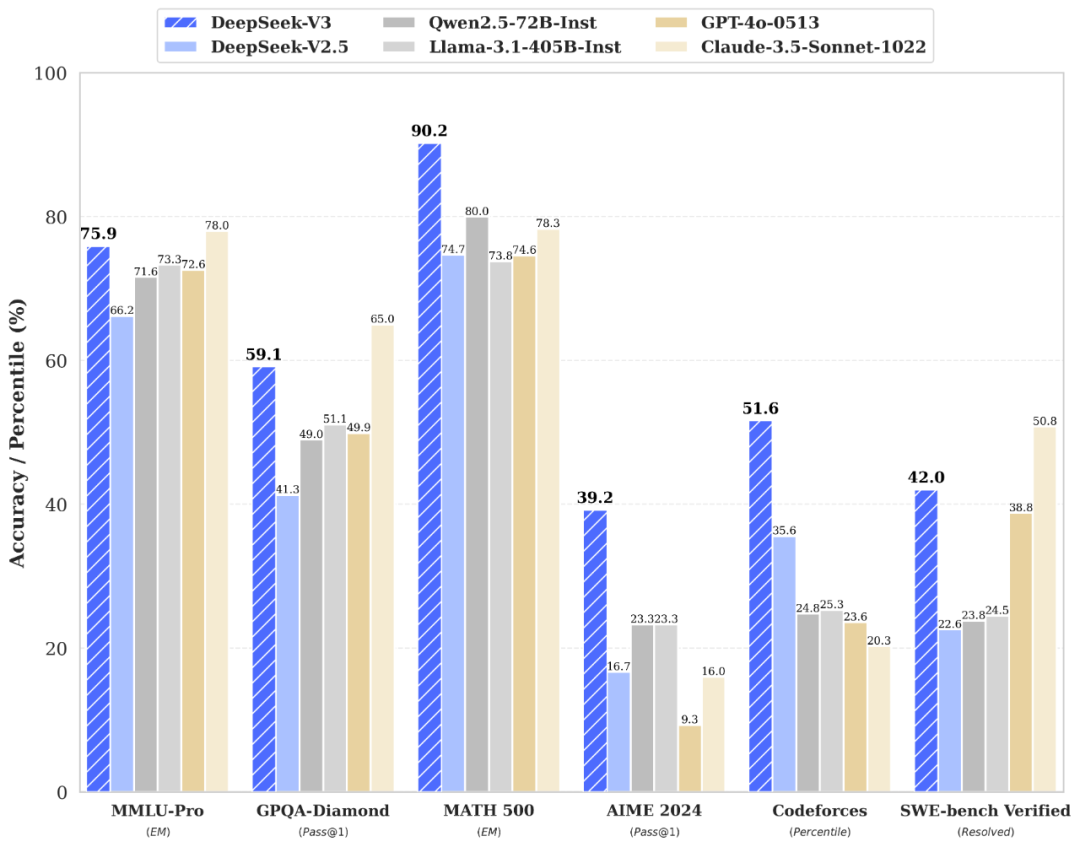
领先的性能表现:DeepSeek-V3 在多个领域展示出顶尖的性能,包括:知识类任务: 在 MMLU、MMLU-Pro 和 SimpleQA 等评测中,DeepSeek-V3 达到与 Claude-3.5-Sonnet 相当的水平,表现极为出色。长文本处理: 在 DROP、FRAMES 和 LongBench v2 等测试中,DeepSeek-V3 超越了大部分模型,特别擅长处理长文本和复杂语境。代码生成: 在算法类代码(Codeforces)场景中,DeepSeek-V3 远远领先于市面上所有非 O1 类模型,在工程类代码(SWE-Bench Verified)中与 Claude-3.5-Sonnet-1022 接近。数学推理: DeepSeek-V3 在美国数学竞赛(AIME 2024)和全国高中数学联赛(CNMO 2024)中大幅领先于所有开源和闭源模型。卓越的中文能力:DeepSeek-V3 在中文任务中同样表现突出,尤其在 C-Eval 教育类测评和 C-SimpleQA 知识类任务中,表现超过了 Qwen2.5-72B,展现了其对中文的深刻理解和处理能力。三倍提升的生成速度:通过算法和工程上的优化,DeepSeek-V3 在生成吐字速度上实现了从 20 TPS 到 60 TPS 的三倍提升,极大改善了用户的交互体验和模型响应速度。开源与本地部署:DeepSeek-V3 开源了原生 FP8 权重,支持社区和开发者进行本地部署。通过与 SGLang、LMDeploy、TensorRT-LLM 和 MindIE 等工具的兼容,用户可以在不同硬件平台上高效运行 DeepSeek-V3,进一步扩展其应用场景。
DeepSeek-V3的性能评测
DeepSeek-V3 多项评测成绩超越了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模型,并在性能上和世界顶尖的闭源模型 GPT-4o 以及 Claude-3.5-Sonnet 不分伯仲。
DeepSeek-V3的项目资源
在线体验:登录官网 chat.deepseek.com 即可与最新版 V3 模型对话。API服务:API 服务已同步更新,接口配置无需改动。论文:https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf代码:https://github.com/deepseek-ai/DeepSeek-V3模型:DeepSeek-V3-Base;DeepSeek-V3
❤️温馨提示:因访问爆满,DeepSeek较为卡顿,经常打不开,推荐一个DeepSeek满血版,免费使用。